
Data is Never Enough
These days, the simplest data processing pipeline implies ingesting data from one place, storing it, and then transforming it by cleaning and validating the data. Only after all this can data be stored properly, and ready to be used for the next purpose. And all these steps precede the data upload to the applications that data analysts and scientists finalize later.
Because data evolves with volume, velocity, and variety, and data-saving tools are constantly updated, sometimes several times a year, data engineers are always in need of finding new ways to process data.
Data is predicted to grow by 44% in the coming years. To predict data trends, engineers need to know:
- How the data will ultimately be used (machine learning model, dashboard, etc.)
- The benefits driving the use of the data
- Where the organization plans to invest their big data analysis
All these variables might affect the engineer’s approach to data processing. There’s no point in predicting trends if data engineers don’t know where the data begins. That’s why we recommend digging deeper to get to know the data better.
A New Path
ETL is a three-phase process where data is first extracted, then transformed, and finally loaded into an output data container. From strategy to realization, data engineering plays a key role in impacting business processes. That’s why data is integrated across functions within an organization.
Modern data engineering has evolved into continuous and collaborative endeavors, spanning multiple teams. Data is now viewed more like a product of software applications. Because of this general shift, new approaches for building and releasing data products have continued to evolve. The term most often used to describe this new workflow is DataOps.
DataOps includes:
- Continuous integration
- Collaborative environments
- Multiple teams
- Product-like aspects
- New approaches
What’s Trending in DataOps?
Trend 1: Automation
The biggest trend in the world of DataOps is automation. Rather than simply focusing on writing ad-hoc (the project that is used to describe work that has been formed or used for a special and immediate purpose, without previous planning) queries or building reports, companies need data engineers to develop an environment surrounded by automation and continuous activity.
Testing and Deployment
This is the main area where data engineers feel the impact of automation. The trend toward more code-based tools and version control makes development more fun and enables testing and development to be automated and run through a few simple commands.
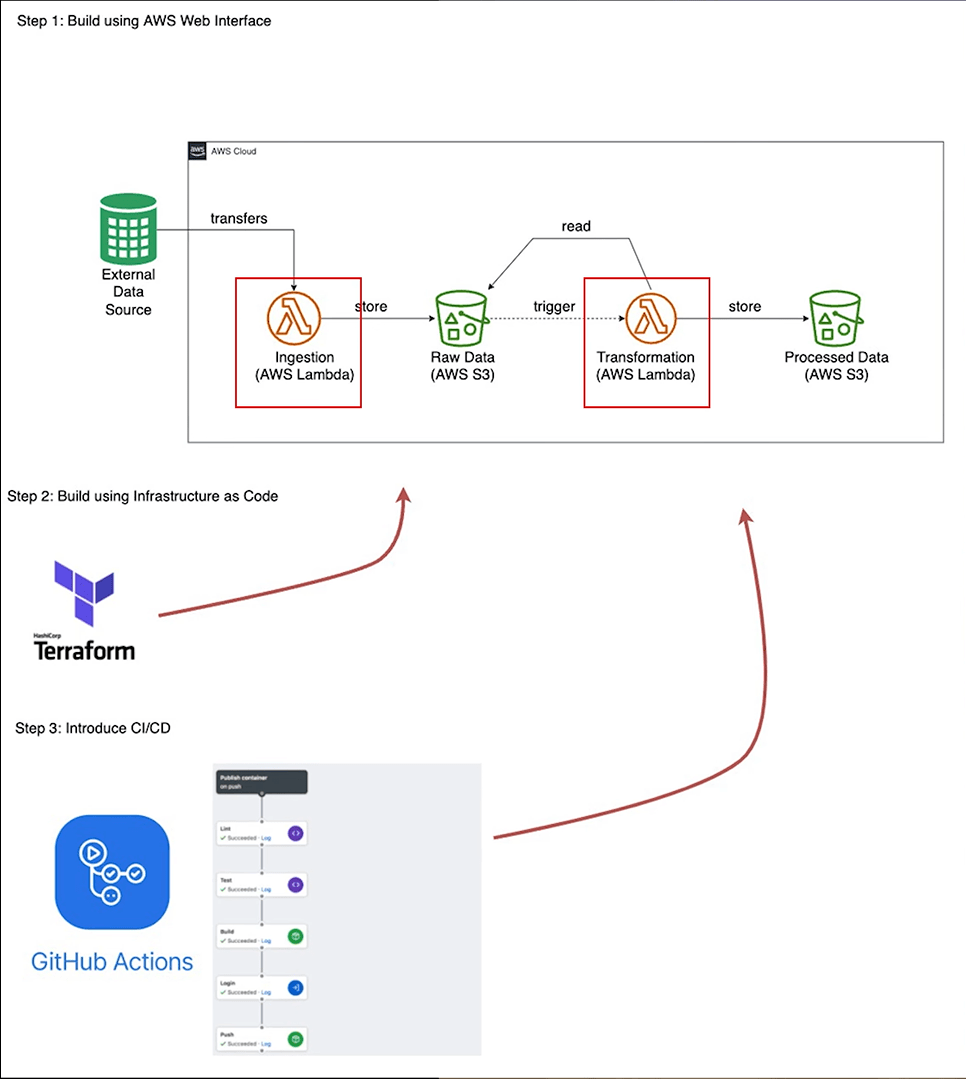
Examples of where you can see this implemented are through GitHub actions or GitLab pipelines. There you can build an automated workflow directly tied to your project code. This approach means more continuous development, testing, and deployment. This is opposed to rigid schedules of deployments and some ad-hoc testing.
Infrastructure
In addition to project testing and deployment, the entire infrastructure can also be automated. Open source tools, like Terraform, allow the user to keep the infrastructure as code and automatically edit and spin up new environments however needed. For example, you can have your environment written in code and automatically deployed through Terraform.
Containerization
This is where you begin getting acquainted with Docker and Kubernetes. Containers allow the user to quickly recreate a very specific environment setup and data engineers can also add it to automated workflows. Here is where engineers can get creative – data specialists can use their containers for testing and deployment. It allows you to automate things that previously would not have been possible.
Scheduling
Scheduling has become much more advanced rather than just being part of an existing tool, like an SQL server agent. These days, entire tools are dedicated to scheduling. Examples include Jenkins, Luigi, and Airflow. Also, you can build a custom script on Python for data engineering. All of these are possible because of a shift toward code-based tools where basic commands can initiate things.
More Data – Faster Processing
This subtopic definitely suits the automation process. As engineers are required to handle more data, the need for better automation increases. If a team wants to find a solution faster, it’s better to use several automated tools to exclude manual actions and make dotted changes to the code.
Trend 2: Integration
Many tools are cloud-based and purposely designed for connectivity and integration. An engineer’s work is heavily focused on ensuring the different platforms used in the stack can properly work together. Here, we’ll review three integration subtopics: triggers, alerts, and multiple tools.
Triggers
This trend in the data world has recently seen multiple individual tools for specific purposes rather than one major tool that does it all. While each individual part is better, the downside is that they don’t all talk to each other unless data engineers specifically tell them to.
Similar to physical manufacturing where the engineer makes sure all the machines are operating in good order and are well-adjusted, data engineers need to ensure that digital machines are working together correctly. The data team can expect a big part of the job to be setting up triggers within a workflow or between tools to be sure everything is running smoothly.
Alerts
With lots of automation going on, there’s a lot more happening behind the scenes, and data engineers can’t always be there to monitor in person. Whether it’s letting you know a job has been successfully completed or alerting you about unexpected errors in running the code, engineers should be able to put systems in place to provide immediate alerts that are then integrated across all the various tools.
A simple example is having integration between scheduling and a team communication tool like Airflow and Slack. Data engineers can set things up so that Airflow results are automatically communicated in Slack and team members don’t have to manually check it or wait on an automated email.
Multiple tools
The modern data stack has changed from one or two primary tools for all functions to a collection of many tools, each with a specific focus. It might be complicated at first but this is where a data engineer gets to build things. This sub-trend can be one of the most rewarding aspects of the job, especially when you see the integration between various tools work the way you intended!
Trend 3: Collaboration
The scope and complexity of data pipelines continue to expand and they’re not just staying within one single data team. On the contrary, the ownership of each part is spread across teams within the data-driven organization.
Shared ownership
In large companies, it’s common practice to have one team dedicated to reporting, another for automation, and another for data modeling. Being able to work in that type of environment is important. A data engineer must have the soft skills needed to collaborate with a variety of people to achieve the goal of the project. The process could look like moving from coordinating development dependencies, releasing the schedule, and letting other team members know if new issues are found during development.
Stakeholder feedback
Receiving direct feedback and support from stakeholders is a natural part of the data science engineering process. Business stakeholders are becoming more data literate and will be more involved in the decision-making process. Another stakeholder could be another development team with their own suggestions because their work directly impacts what the data engineers build. This sub-trend allows for collaborative work and a fluid environment, which is opposite to the traditional model of hiding the process behind the scenes.
Dictionaries & lineage
With the growing complexity of the data pipelines that engineers are now building, getting things done right requires team collaboration to sync everything together and ensure that definitions and lineages are accurate.
Many new tools, like DBT, have built-in concepts, but there are other ways to accomplish this. Data engineers of 2023 could create shared document sites, a custom hosted website or even an internal wiki. There are many tools available, but generally, documentation is essential to consider as part of the development process, not as an afterthought.
Trend 4: Personalization
Using more cloud space is an option to make it happen, organizations should consider using personal tools. Creating individual programs will save much time from the perspective of cluster handling and the data volume inside.
When data engineers use independent, all-purpose tools, they simplify their work with higher scalability and performance and will help improve their systems to include more natural language processing or even real-time analytics.
Trend 5: Better Testing Solutions
The Trino testing tool is crucial for up-to-data engineers. Using the Pytest (one of the most popular frameworks for testing python code), a specialist can run a unit test for verification as well as a massive load test for profile data. Constantly tuning data infrastructure lowers query execution time so an engineer can be more confident in experiments.
Although Trino is a distributed system on a huge scale, it’s still difficult to test. But with setup tools, specialists can abstract away all the complex details to write Pytest and unit tests, which are familiar patterns for most engineers.
Data Experiments: Driven By Growth
Because a data engineer is typically responsible for both designing and building data processing pipelines, the role is generally a mix of software engineering, DevOps, and machine learning. As the demand for data engineering specialists has grown by close to 40%, putting it fourth in demand behind blockchain engineer, security engineer, and embedded engineer. By understanding the current trends in the field, data engineering candidates can feel more confident and aware of working in this new way.
These trends have already affected modern organizations. Teams looking to grow globally should be seeking to execute more efficient processes as well as fine-tuning soft skills like flexibility and collaboration.
Newfire is Always Up to Data
Newfire’s corporate spirit embodies a work-hard/play-hard mentality. Our data engineers constantly experiment with various tools to reach optimal results, so no matter what technologies you’ve used previously, it’s critical to support fellow team members and to be open to learning new things.
Experimentation becomes easier as we grow, and our Newfire data engineers are always happy to “talk shop” about the various tips and tweaks they use to make their work most successful. We’d love to hear more from you on the topic, to learn about your challenges and opportunities in the field. And, our data engineering team is expanding globally! We encourage you to search for openings and apply so we can develop more trends together!

